

On Halloween Google decided to spook users of it’s Google Docs service when they came to find themselves locked out of their accounts due to a Terms of Service (ToS) violation. It just goes to show that many giant corporations like Facebook, Google, Twitter, and others abuse your privacy and data. Whether it is monitoring your google docs in this case or using your data to make money that you never see a dime of.
Some people who had their documents blocked took to Twitter to figure out why their documents were blocked.

Rachael Bale couldn’t have said it better, “though clearly very naive of me not to have considered it before…”
Bhaskar Sunkara was writing a paper on Eastern European post-socialist parties and it managed to violate Google’s Terms of Service after the new code was implemented.
A statement from Google Tuesday said the cause behind Google Docs being locked was from a new code implemented that accidentally flagged Google Docs as “abusive”, so it automatically blocked those documents. The code was fixed later on, so users could gain access back to their files that are locked.
Per a Google spokesperson on Google Docs being scanned: “We do not technically read files, but instead uses an automated system of pattern matching to scan for indicators of abuse. Though it can identify clusters of data that might suggest a violation, the system does not pull meaning from the content.”
Google offered a public apology on Thursday, after users were blocked by Google’s malware bug caused by a change in code applied on October 31st. Google’s Director of Product Management, Mark Rishner wrote a blog post explaining Googles apology and protecting it’s users against spam, malware, and viruses for cyber-security. The blog post states how the anti-malware scans documents to protect users:
“The Google Docs and Drive products have unparalleled automatic, preventive security precautions in place to protect our users from malware, phishing and spam, using both static and dynamic antivirus techniques. Virus and malware scanning is an industry best practice that performs automated comparisons against known samples and indicators; the process does not involve human intervention.”
Though it appeared to be a technical glitch for the most part, Google was able to identify “bad” Google Docs should serve as a reminder, that almost everything you do on Google is monitored, recorded, and stored. Gmail recently this summer stopped scanning emails for advertising purposes, a practice that dates back years for Google. Scanning through Gmail allows them to suggest responses to emails among other things.
Data is big money for Google and allows Alphabet (Google Parent Company) to stay afloat. Per Alphabet’s 2016 annual report, Google Advertising made up 88% of all revenue.
Either way you look at it, Google is clearly quite invasive in users activities on their platform. You can find out about what information they collect in their Privacy Policy. In here Google states the type of information they collect:
We collect information to provide better services to all of our users – from figuring out basic stuff like which language you speak, to more complex things like which ads you’ll find most useful, the people who matter most to you online, or which YouTube videos you might like.
Google is very upfront in their privacy policy about the types of data they use and how they use it. Under the information they collect, there is a whole list of information they collect from Google’s services including: device information, log information, location information, unique application numbers, local storage, and cookies.
Decentralized Storage
My last article covered the current decentralized storage options and went in depth how they will improve the lack of trust we have with current storage providers. There are four projects in the space: Filecoin, Maidsafe, Storj, and Siacoin. The photo below describes the general concept of the decentralized cloud.
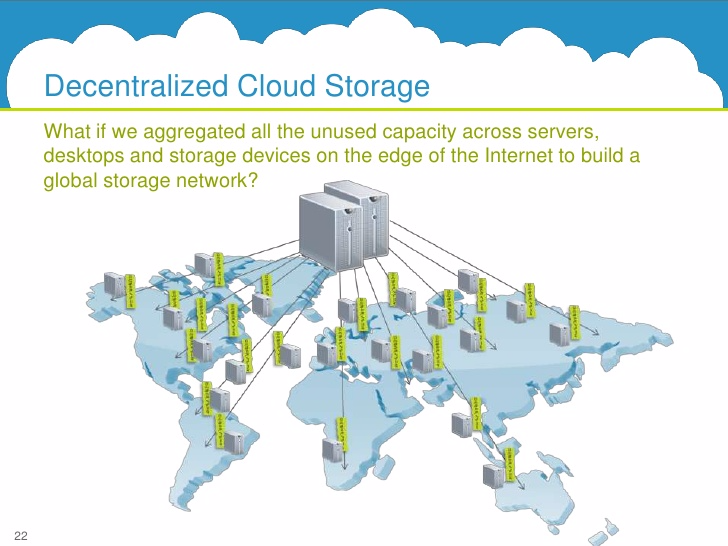
All four run on the same premise of renting out hard drive space for tokens on their platforms. This means anyone can rent out hard drive space and provide storage for the networks, giving them cheaper pricing than current centralized options who set arbitrary prices versus the supply and demand model of decentralized storage. The advantage decentralized storage offers is your data being free of tampering from third parties. Maidsafe and Siacoin emphasize autonomous networks free of human interaction.
These networks are still in their infancy, but they are growing. Every project besides Filecoin offers a working product currently where you can store data for a fraction of the cost of what centralized storage providers are offering. This is where they will win in the long term, there prices are very attractive and many businesses will see an opportunity to cut data storage costs.
The Future
People have a hard time accepting or seeing change. It’s not easy, but the same goes here. As large as Google, Amazon, IBM, Dropbox, and others may seem, there will be a competitor or competitors that will disrupt their data storage services. This doesn’t mean data centers will become obsolete, as they will still be vital in storing data for certain enterprises, for example data warehousing and high volume, low latency transactions.
22 years ago, we still had to code to send an email, now we send emails at a whim without thinking about the process that goes into sending an email. We are on the dawn of major disruption throughout data storage over the next decade. It may happen sooner, but I’d rather be conservative here on my estimate. One of the four names I listed above will be the backbone storage layer of the internet, and you likely won’t even know, but they’ll be providing the storage for the Netflix series you’re watching.
Think about how far smart phones have come over the past decade from 2007. The iPhone had just come out and many in business were using a Blackberry; when was the last time you saw a Blackberry phone? Exactly, now we are all glued to are smart phones 24/7 and can’t seem to get away from them as they get more incorporated into are everyday lives. Technology disruption time frames keep shrinking as technology increases.
In total, this is a reminder if you want to keep your documents private, keep them offline and store them on your own, otherwise you run the risk of having your information breached. Google is slowly becoming the Standard Oil of the 21st century, in a way that it controls a majority of the internet advertising to searches whereas Standard Oil controlled oil refineries to railroads and other industries with their gigantic size and power.
This is a Contributor Post. Opinions expressed here are opinions of the Contributor. Influencive does not endorse or review brands mentioned; does not and cannot investigate relationships with brands, products, and people mentioned and is up to the Contributor to disclose. Contributors, amongst other accounts and articles may be professional fee-based.